From niche to mainstream: How big data became global research powerhouse
This acceleration coincided with a broader digital transformation, including the rise of the web, the advent of distributed processing systems like Hadoop, the proliferation of smartphones and IoT devices, and the integration of artificial intelligence and machine learning into mainstream applications. These technological and social shifts created fertile ground for big data to emerge as a powerful cross-cutting research paradigm.
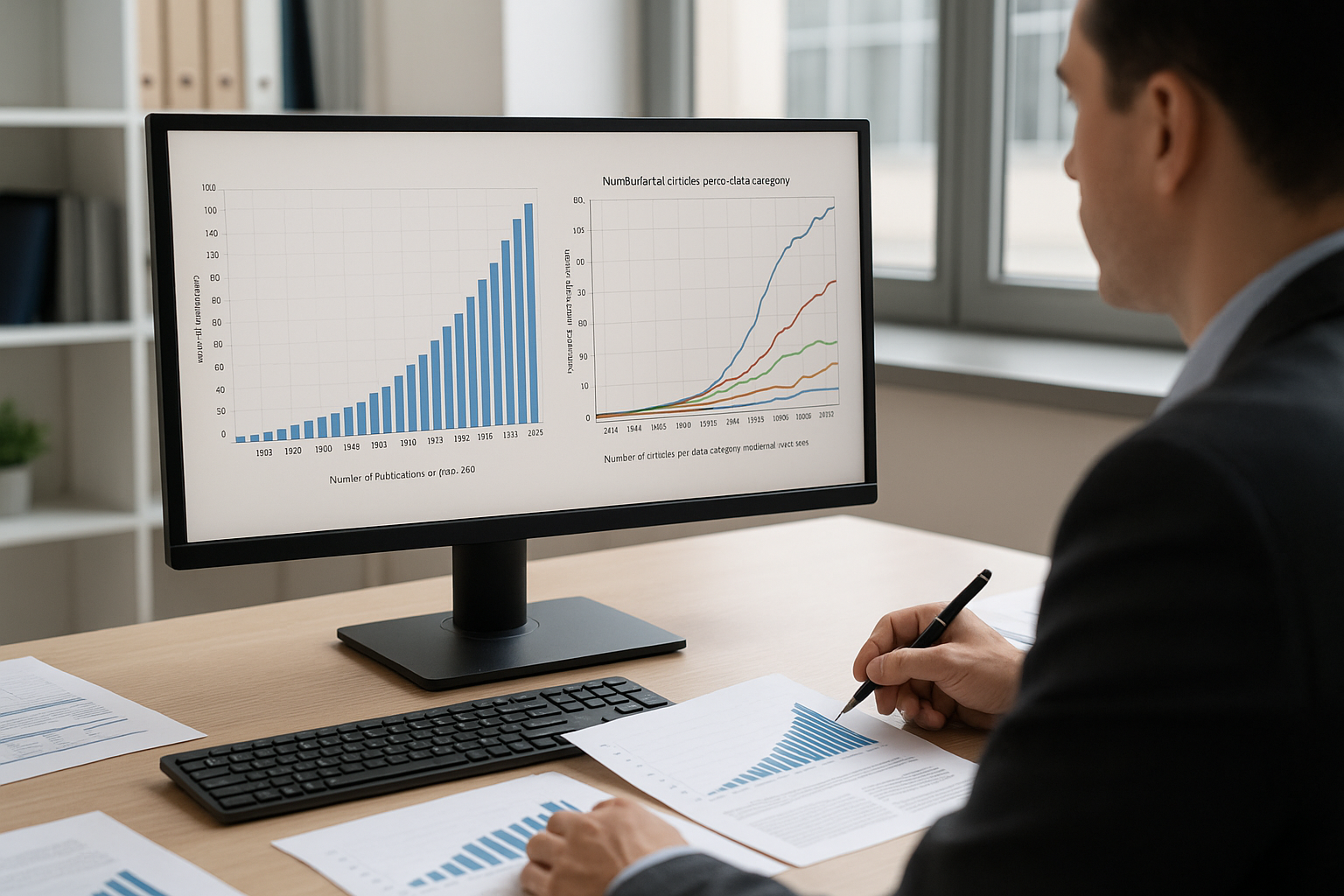
A new analysis reveals how “big data” has transformed from a niche academic interest into a dominant interdisciplinary research field. The work charts 30 years of growth, mapping the field’s conceptual landscape and uncovering the dynamics that have fuelled its rapid expansion across the sciences.
Published in Metrics, the study "Thirty Years of Big Data Research: A Scientometric Analysis of the Field’s Growth, Interdisciplinarity, and Conceptual Landscape (1993–2022)" draws on an extensive dataset of 70,163 peer-reviewed articles and 315,235 author keywords indexed in Scopus. It offers one of the most comprehensive examinations to date of the intellectual and disciplinary foundations underpinning big data research.
Mapping the growth of a global research phenomenon
The study identifies two clear phases in big data’s academic evolution. The first, spanning 1993 to 2012, was characterised by slow and incremental growth, with annual publication counts in the low hundreds. The second, from 2013 to 2022, marked an explosive surge, driven by technological breakthroughs and the widespread adoption of data-intensive methods. In this later phase, 91.7 per cent of all publications were produced, with yearly outputs climbing from 127 in the early 1990s to over 10,000 by 2022.
This acceleration coincided with a broader digital transformation, including the rise of the web, the advent of distributed processing systems like Hadoop, the proliferation of smartphones and IoT devices, and the integration of artificial intelligence and machine learning into mainstream applications. These technological and social shifts created fertile ground for big data to emerge as a powerful cross-cutting research paradigm.
The analysis also underscores the centrality of the “big data” concept itself, which serves as the most dominant category in the field’s conceptual network. This core is closely linked to related terms such as machine learning, deep learning, artificial intelligence, and cloud computing, reflecting how computational and algorithmic advances have become inseparable from the big data discourse.
Interdisciplinary expansion and conceptual consolidation
By examining the subject classifications in SCImago, the researchers reveal that big data is not confined to a single discipline but spans physical sciences, social sciences, health sciences, and life sciences. Importantly, interdisciplinarity has deepened over time, with increasing numbers of studies combining expertise from multiple domains. This blending of disciplines is not just incidental - it has been integral to big data’s capacity to address complex, multifaceted challenges.
The study’s methodology goes beyond counting publications. Using an abductive, literature-informed protocol, the authors built a framework of 17 interconnected “digital data” categories, each representing a distinct but related strand of research. These range from well-established areas such as social media data and intelligent data to emerging niches like smart data and digital footprints. By mapping co-occurrences between these categories and their associated keywords, the researchers identify how certain themes have risen in prominence, merged, or diverged over time.
The findings indicate that while big data serves as the gravitational centre of the field, the surrounding ecosystem of concepts is dynamic and adaptive. New categories have emerged in response to shifts in technology and societal needs, while others have been absorbed into the mainstream of big data discourse. This evolution suggests that the field is not static but continually reshaping itself in line with both technical possibilities and research priorities.
Implications for research, policy, and future development
The study offers guidance for researchers, policymakers, and funders. For scholars, the analysis highlights the value of strategically combining core big data terminology with more specific thematic categories to enhance visibility and reach across disciplines. Such positioning can be particularly advantageous in capturing the attention of interdisciplinary audiences and aligning with funding priorities that increasingly favour cross-sector collaboration.
For research funders and policymakers, the sustained growth trajectory underscores the necessity of continued investment in big data infrastructure, skills development, and collaborative networks. The authors argue that the field’s demonstrable impact across diverse domains - from health and mobility to environmental monitoring, justifies long-term strategic support. This includes fostering collaborations that bridge traditional disciplinary boundaries and ensuring that ethical, privacy, and governance considerations keep pace with technical innovation.
The study also draws attention to areas where research remains underdeveloped. While certain applications and methodologies, such as machine learning and cloud computing, have matured rapidly, other strands, especially those involving niche data sources or underexplored ethical dimensions, have yet to achieve the same level of scholarly integration. These gaps represent opportunities for pioneering work, particularly for early-career researchers and institutions seeking to carve out distinctive areas of expertise.
Another notable insight is the shifting geography of big data research. Although North America and Europe remain central hubs, there has been significant growth in contributions from Asia, reflecting the globalisation of the field. This diversification of research origins suggests a broader range of perspectives, datasets, and application contexts, which could further enrich the field’s problem-solving capacity.
The authors also acknowledge the study’s limitations. Coverage is restricted to peer-reviewed journal and review articles indexed in Scopus, meaning that conference papers, technical reports, and grey literature are excluded. Moreover, the dataset reflects the state of indexing as of late 2023, with full coverage extending only to the year 2022 due to indexing lags. Despite these constraints, the curated dataset, made available as supplementary material, offers a valuable resource for secondary analysis and future bibliometric studies.
- FIRST PUBLISHED IN:
- Devdiscourse









